 CurrentLine AI Weekly
CurrentLine AI Weekly
In the past two to three months, there has been a flurry of activity, culminating in the elevation of AI’s language comprehension capabilities to several new heights.
If this pace seems overwhelming, it’s understandable.
However, as users and developers, we stand to gain from these advancements as they lead to more intelligent, cost-effective, and accessible LLMs and AI agents.
The discussion about whether LLMs truly ‘understand’ human text to a degree that makes them highly useful is largely settled. They do. They have mastered logic and human knowledge while improving the accuracy of their next word predictions. This is widely recognized by those interested in business efficiency and personal learning. Moreover, developers are eager to incorporate LLMs into their applications.
In essence, virtually every prediction made by Natural Language Understanding (NLU) specialists, including myself in this very blog, based on the R&D from our startup, has already come to pass, often at a quicker pace than anyone anticipated.
Now, we have:
• Advanced GPT applications with improved accuracy, thanks to ‘iterative’ or ‘chain of thought’
(COT) prompting
• Open source alternatives to GPT that are nearly as efficient, but thousands of times smaller
• LLMs that operate on laptops or smartphones without the need for GPUs
• AGI-based applications developed from GPT and open source
• Add-ons for GPT like Wolfram Alpha
I had been utilizing chain-of-thought before it became mainstream, as discussed here. I faced considerable criticism for predicting the emergence of AGI-like applications in 2023.
Now, let’s delve into the specifics, methodologies, rationales, and contributors behind these developments.
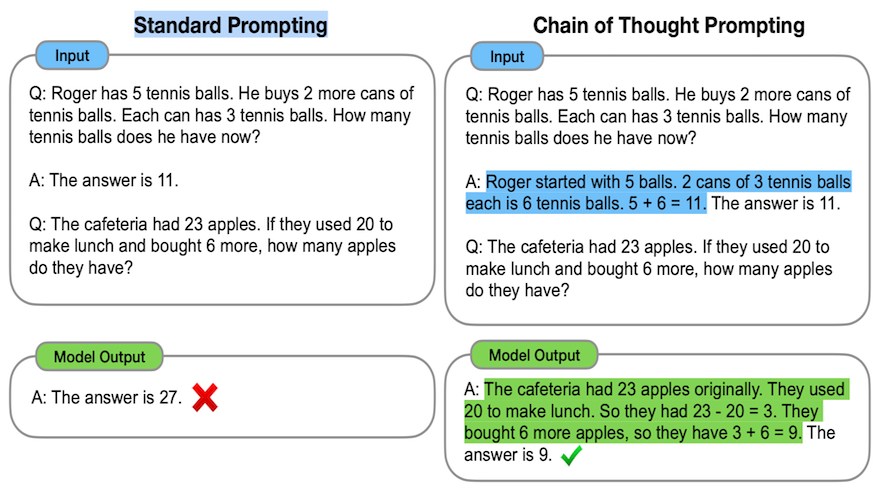
Chain of Thought (COT)
OpenAI’s GPT-4 still remains the most accurate LLM, standing a considerable 10-20% ahead of Google’s Bard, depending on your measurement criteria.
Subsequently, hobbyists, startups, and major corporations have experimented with prompts and application structures that engage GPT in stages to simulate human-like, step-by-step thinking, as per my suggestions based on AGI experiments conducted in October 2022.
This methodology has now been termed Chain of Thought (COT).
Interestingly, this major enhancement only involves improved prompts followed by cycles of alternate generative attempts and reviews. Rather than a single ChatGPT prompt or API call, you’d need about five to achieve this. However, forthcoming COT applications will hide this complexity from the end user.
Soon, this technology could be extended further, allowing users to delegate a whole month’s worth of data cleaning, research, development, or content creation to an app for a mere $10. This could be completed in a matter of minutes, with users then reviewing the results and interim outcomes carefully.
This is entirely plausible.
Example of COT Prompts
The primary goal is to develop universal prompts, concealed within third-party LLM applications, that guide the LLM in a sequential manner.
As an end user or developer, you would not want to write a specific prompt each time, other than specifying the final objective.
Also, rather than supplying the LLM with complex ‘few-shot’ examples, developers and researchers are finding that COT and advanced prompting techniques can render this unnecessary.
GPT merely required additional time to explore various perspectives. As efficient as GPT is, it cannot execute everything in a single call, resembling its triumphs and trials with arithmetic calculations at and beyond the 4×4 digit multiplication level.
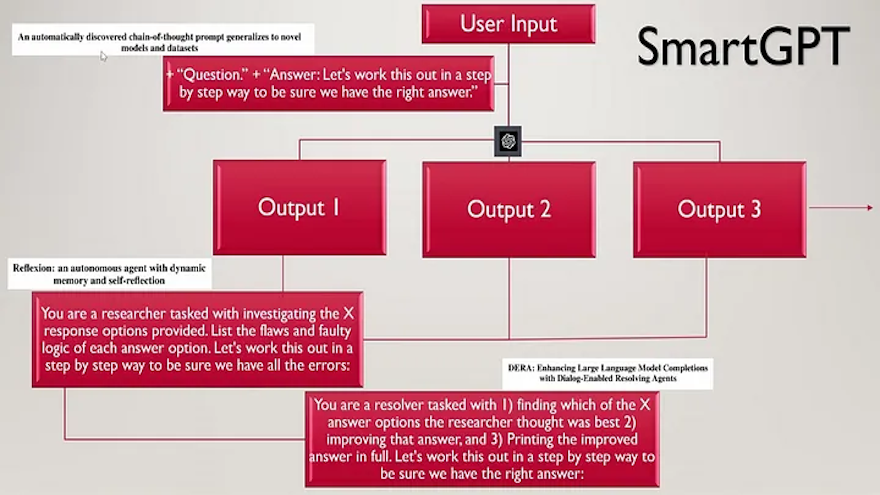
Applications like the one created by AI Explained, currently in a (public!) ‘stealth’ mode, have substantially increased the accuracy of GPT-4 by internally prompting the LLM to:
• Proceed step-by-step
• Generate multiple attempts (utilizing LLM stochastics)
• Review each attempt for errors
• Determine the best attempt
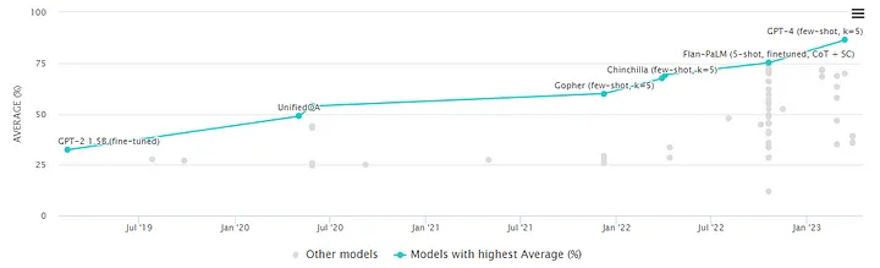
The beauty of this is that it improves accuracy by 10-20% on complex problems, often evaluated on the Massive Multitask Language Understanding (MMLU) dataset.
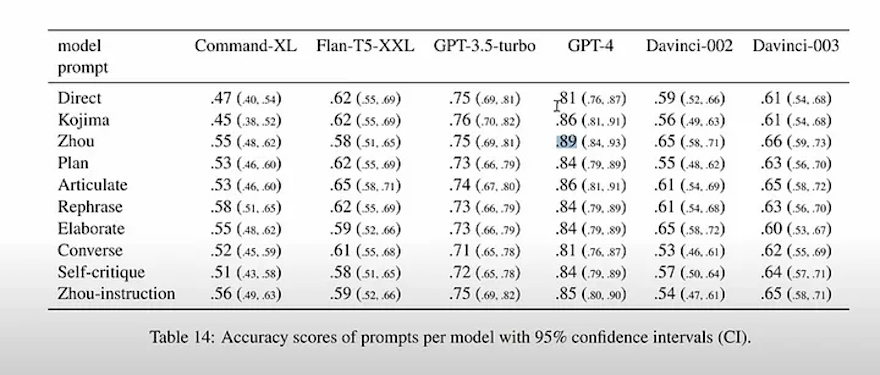 GPT-4’s accuracy rising from 81% to 86%, then to 89% upon the addition of (Kojima) and improvement of (Zhou) COT prompts, even before the review and resolution stage.
GPT-4’s accuracy rising from 81% to 86%, then to 89% upon the addition of (Kojima) and improvement of (Zhou) COT prompts, even before the review and resolution stage.
The Meta LLAMA Incident
Concurrently, or shortly after, a surprising incident took place. Meta, the dark horse of the industry, experienced a leak involving their LLM, LLAMA, including their training weights, in February 2023.
Following this, hobbyists and startup specialists have built upon it and developed versions that perform nearly as well as GPT-4 but with significantly fewer parameters, 1000 times less, to be precise.
Furthermore, they’ve tailored these versions to operate solely on CPUs, eliminating the need for GPUs.
This implies that capable LLMs can even run locally on mobile devices.
There is speculation that Meta may have orchestrated the leak intentionally to benefit from open-source enhancements for their internal models. If this were the case, they would be the only ones legally allowed to use it, given that the leak was technically unlawful.
While I find it unlikely that Meta could be so clever, cunning, or desperate, nothing can be ruled out entirely.
Google Leak
The AI landscape appears to be as leaky as a sieve at present.
Recently, an internal white paper intended for Google’s LLM teams was leaked. This document disclosed:
• Google is trailing in the LLM race
• Open source is the preferred strategy
• Rapid optimization of ‘small’ (20B parameter) LLM models is far superior to a slow, perfectionist
approach on large (200B parameter) LLMs
• Google doesn’t believe OpenAI will be able to keep up
While I concur with these insights, I still believe OpenAI — a specialist in GPT development — will fare reasonably well. However, the recent surge in high-performance, compact LLM models may pose a challenge.
Consequences for Users and Developers
As users, we should anticipate:
• The advent of more AGI-like applications acting as intelligent agents, working directly on your
files and data
• ChatGPT-like services boasting improved accuracy through internal use of COT
• Mobile applications equipped with built-in LLM functionality and low latency, eliminating the need
to access GPT APIs
• More affordable premium LLM services, implying a decrease in GPT-4’s price
As developers, we can expect:
• Soon to have access to pre-trained open source LLMs that deliver performance within 10% or 20% of
GPT-4’s accuracy, allowing us to fine-tune them
• This means our applications will not depend on GPT or incur API charges. If we use a third-party
service, the API charges will be significantly lower
• The opportunity to develop LLM-based mobile applications
The only potential hurdle could be if Meta’s base code becomes illegal to use. Keep an eye on this space for updates.
